This post will discuss the ruby gem
sort_authority and the problem it
aims to solve, which is how to quickly sort mixed number and letter strings in
Ruby in a "human" way.
The problem is easiest to explain with images.
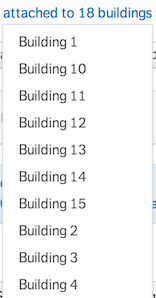
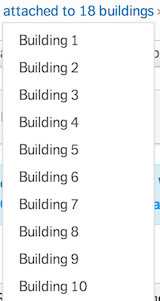
Which would you rather see in an application?
This?
or this?
As Jeff Atwood noted in this blog post
from way back in 2007, this is the difference between "ASCIIbetical" and
alphabetical sorting. When creating an interface for humans with listings
containing a mix of letters and numbers you almost always want the latter and
not the former. Yet real alphabetization (also refered to as "natural" or
"human" sorting) is typically not included in standard libraries, Ruby's
included.
As the developer involved in implementing natural sorting for our app at
WegoWise I first turned to the solution presented
here, which we'll call
sensible_sort. This algorithm works fine1, in that it does in fact sort
strings alphabetically. There are also plenty of gems we could have used as
well, including naturalsort,
naturally2, and
natcmp.
Any of these approaches would have gotten the job done, but my coworker
Nathan took one look at the pull request and asked
me how well the algorithm performed. I shrugged3; I hadn't worried about
performance because the lists I was sorting were so small. Then I signed off
for the day.
By the next morning Nathan had thrown together some benchmarks that showed that
sensible sort could be fairly slow given a long enough list. The other Rubygems
didn't perform very well either, compared to Ruby's native ASCIIbetical sort
and a C algorithm by Martin Pool called
natsort. In fact,
Nathan had gone even further and made a wrapper for natsort using FFI,
labeled strnatcmp.c below. Behold the damning numbers:
Considering that we're talking about 100,000 items maybe 2 seconds isn't that
bad. We don't have user-facing lists that have 100,000 elements... yet. Also,
I had developed a sentimental attachment to sensible_sort and decided to
write a more realistic benchmark involving randomized strings (gist here),
resulting in the following numbers:
Sorting 100,000 strings like this: "9 3q1q05_xsfw87i6wf7"
(This benchmark was made a while ago on Ruby 1.9.2 but results hold for later
Rubies)
I was pleased to note that sensible_sort is not the worst approach in
this benchmark. But it's also not very good. 21 seconds is pretty much
unacceptable for an operation you might want to do inside a page request.
Again, we don't often have to sort 100,000 items for humans these days, but
this is an extension on the core Enumerable module that might get used in
various contexts throughout the application. If we can avoid an inherently slow
approach in favor of a painless alternative, why wouldn't we?
And that's how the
sort_authority4
gem came about. sort_authority is just a simple wrapper around strnatcmp.c,
plus an extension on Enumberable to add #natural_sort and #natural_sort_by
methods on arrays and such. If you care about sorting lists in a sane order
(and you should) and want it to be almost as fast as regular sort (why not?)
then you should give it a try.
Although some changes involving type coercion were required to update the code for Ruby 1.9+, available in this gist).↩
Which has the distinction of being one of the least googleable Rubygems.↩
Well, our team is mostly remote so this communication took place in the form of emoticons and animated gifs in our chat room, but same idea.↩
At WegoWise we use extensive code review feedback to iteratively improve code.
I want to describe how Git fits into this process, because this is probably the
biggest change I had to make to my preexisting workflow when I came on board.
Basically I had to relearn how to use Git. The new way of using it (that is, it
was new to me) is extremely powerful and in a strange way extremely satisfying,
but it does take a while to get used to.
Importance of rebasing
I would describe my old approach and understanding as ”subversion, but with
better merging” 1 . I was also aware of the concept of rebasing from having
submitted a pull request to an open source project at one point, but I didn’t
use it very often for reasons I’ll discuss later. As it turns out understanding
git rebase is the key to learning how to use Git as more than a ‘better
subversion’.
For those who aren’t familiar with this command, git rebase <branch> takes
the commits that are unique to your branch and places them “on top” of another
branch. You typically want to do this with master, so that all your commits
for your feature branch will appear together as the most recent commits when
the feature branch is merged into master.
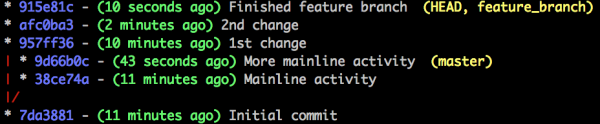
Here’s a short demonstration. Let’s say this is your feature branch, which
you’ve been developing while other unrelated commits are being added to master:
If you merge without rebasing you’ll end up with a history like this:
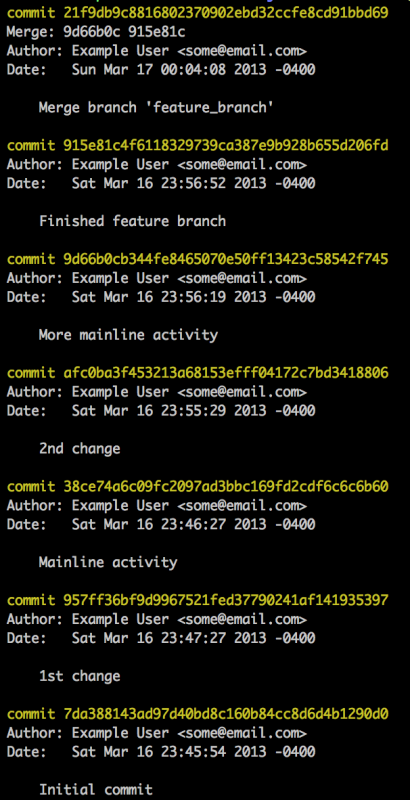
Here is the process with rebasing:
# We're on feature_branch
git rebase master # Put feature_branch's commits 'on top of' master's
git checkout master
git merge feature_branch
This results in a clean history:
Another benefit of having done a rebase before merging is that there’s no need
for an explicit merge commit like you see at the top of the original history.
This is because — and this is a key insight — the feature branch
is exactly like the master branch but with more commits added on. In other
words, when you merge it’s as though you had never branched in the first place.
Because Git doesn’t have to ‘think’ about what it’s doing when it merges a
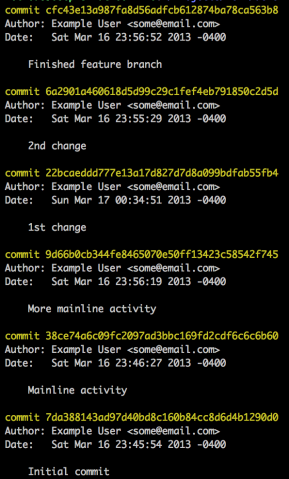
rebased branch it performs what is called a fast forward. In this case
it moved the HEAD from 899bdb2 (More mainline activity) to 5b475e
(Finished feature branch).
The above is the basic use case for git rebase. It’s a nice feature that keeps
your commit history clean. The greater significance of git rebase is the way it
makes you think about your commits, especially as you start to use
the interactive rebase features discussed below.
Time travel
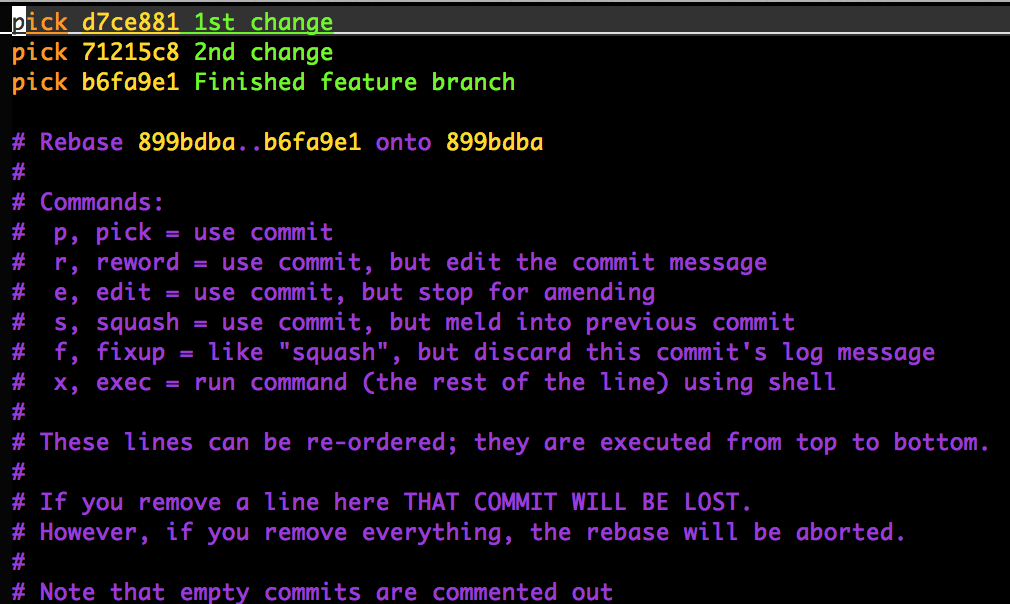
When you call git rebase with the interactive flag, e.g. git rebase -i master,
git will open up a text file that you can edit to achieve certain effects:
As you can see there are several options besides just performing the rebase
operation described above. Delete a line and you are telling Git to disappear
that commit from your branch’s history. Change the order of the commit lines
and you are asking Git to attempt to reorder the commits themselves. Change the
word pick to squash and Git will squash that commit together with the
commit on the preceding line. Most importantly, change the word pick to
edit and Git will drop you just after the selected ref number.
I think of these abilities as time travel. They enable you to go back in the
history of your branch and make code changes as well as reorganize code into
different configuration of commits.
Let’s say you have a branch with several commits. When you started the branch
out you thought you understood the feature well and created a bunch of code to
implement it. When you opened up the pull request the first feedback you
received was that the code should have tests, so you added another commit with
the tests. The next round of feedback suggested that the implementation could
benefit from a new requirement, so you added new code and tests in a third
commit. Finally, you received feedback about the underlying software design
that required you to create some new classes and rename some methods. So now
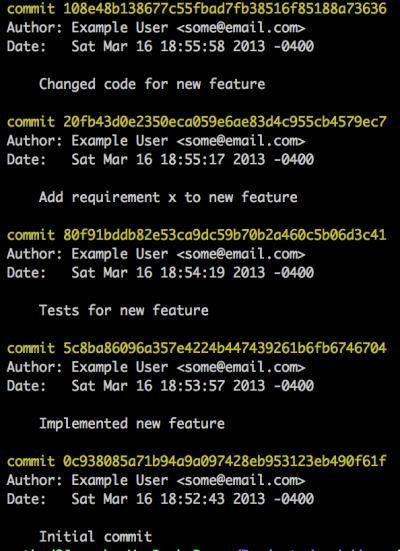
you have 4 commits with commit messages like this:
Implemented new feature
Tests for new feature
Add requirement x to new feature
Changed code for new feature
This history is filled with useless information. Nobody is going to care in the
future that the code had to be changed from the initial implementation in
commit 4 and it’s just noise to have a separate commit for tests in commit 2.
On the other hand it might be valuable to have a separate commit for the added
requirement.
To get rid of the tests commit all you have to do is squash commit 2 into
commit 1 (by entering interactive rebase and changing the word pick on the
second commit to squash or just s3), resulting in:
Implemented new feature
Add requirement x to new feature
Changed code for new feature
New commit 3 has some code that belongs in commit 1 and some code that belongs
with commit 2. To keep things simple, the feature introduced in commit 1 was
added to file1.rb and the new requirement was added to file2.rb. To handle
this situation we’re going to have to do a little transplant surgery. First we
need to extract the part of commit 3 that belongs in commit 1. Here is how I
would do this:
# We are on HEAD, i.e. commit 3
git reset HEAD^ file1.rb
git commit --amend
git stash
git rebase -i master
# ... select commit 1 to edit
git stash apply
git commit -a --amend
git rebase --continue
It’s just that easy! But seriously, let’s go through each command to understand
what’s happening.
The first command, git reset, is notoriously hard to explain, especially
because there’s another command, git checkout, which seems to do something
similar. The diagram at the top of this Stack Overflow
page is
actually extremely helpful. The thing about Git to repeat like a mantra is that
Git has a two step commit process, staging file changes and then actually
committing. Basically, when you run git reset REF on a file it stages the
file for committing at that ref. In the case of the first command, git reset
HEAD^ file.rb, we’re saying “stage the file as it looked before HEAD’s
change”; in other words, revert the changes we made in the last commit.
The second command, git commit --amend commits what we’ve staged into
HEAD (commit 3). The two commands together (a reset followed by an amend) have
the effect of uncommitting the part of HEAD’s commit that changed file1.rb.
The changes that were made to file1.rb aren’t lost, however. They were
merely uncommitted and unstaged. They are now sitting in the working directory
as an unstaged diff, as if they’d never been part of HEAD. So just as you could
do with any diff you can use git stash to store away the diff.
Now I use interactive rebase to travel back in time to commit 1. Rebase
drops me right after commit 1 (in other words, the temporary rebase HEAD is
commit 1).
I use git stash apply to get my diff back (you might get a merge conflict
at this point depending on the code).
Now I add the diff back into commit 1 with git commit --amend -a (-a
automatically stages any modified changes, skipping the git add . step).
This is the basic procedure for revising your git history (at least the way I
do it). There are a couple of other tricks that I’m not going to go into detail
about here, but I’ll leave some hints. Let’s say the changes for the feature
and the new requirement were both on the same file. Then you would need to use
git add --patch file1.rb before step 2. What if you wanted to introduce a
completely new commit after commit 1? Then you would use interactive rebase to
travel to commit 1 and then add your commits as normal, and then run git
rebase --continue to have the new commits inserted into the history.
Caveats
One of the reasons I wasn’t used to this workflow before this job was because I
thought rebasing was only useful for the narrow case of making sure that the
branch commits are grouped together after a merge to master. My understanding
was that other kinds of history revision were to be avoided because of the
problems that they cause for collaborators who pull from your public repos.
I don’t remember the specific blog post or mailing list message but I
took away the message that once you’ve pushed something to a public repo (as
opposed to what’s on your local machine) you are no longer able to touch that
history.
Yes and no. Rebasing and changing the history of a branch that others are
pulling from can cause a lot of problems. Basically any time you amend a commit
message, change the order of a commit or alter a commit you actually create a
new object with a new sha reference. If someone else naively pulls from your
branch after having pulled the pre-revised-history they will get a weird set of
duplicate code changes and things will get worse from there. In general if
other people are pulling from your public (remote) repository you should not
change the history out from under them without telling them. Linus’ guidelines
about rebasing
here are
generally applicable.
On the other hand, in many Git workflows it’s not normal for other people to be
pulling from your feature branch and if they are they shouldn’t be that
surprised if the history changes. In the Github-style workflow you will
typically develop a feature branch on your personal repository and then submit
that branch as a pull request to the canonical repository. You would probably
be rebasing your branch on the canonical repository’s master anyway. In that
sense even though your branch is public it’s not really intended for public
consumption. If you have a collaborator on your branch you would just shoot
them a message when you rebase and they would do a “hard reset” on their branch
(sync their history to yours) using git reset --hard
remote_repo/feature_branch. In practice, in my limited experience with a
particular kind of workflow, it’s really not that big a deal.
Don’t worry
Some people are wary of rebase because it really does alter history. If you
remove a commit you won’t see a note in the commit history that so and so
removed that commit. The commit just disappears. Rebase seems like a really
good way to destroy yours and other people’s work. In fact you can’t actually
screw up too badly using rebase because every Git repository keeps a log of the
changes that have been made to the repository’s history called the reflog.
Using git reflog you can always back out misguided recent history changes by
returning to a point before you made the changes.
Hope this was helpful!
Note: a different version of this post was posted on the author's blog Stupid Idea.
Not an insignificant improvement, since merging in Subversion sucks.↩
Which I always think about as a hard drive head, which I in turn think about as a record player needle.↩
Or use f for fixup to combine the two commits but only use the commit message from the first.↩
The WegoWise team spends a lot of time talking about names. We try to pick
variable, class and method names that express not only the function but also
the intention of code. The idea is that good names help other developers by:
Helping them reason about the code at a high level. Good names combined with
short methods should approach the readability of pseudocode.
Reducing the need for extra comments, which tend to get out of sync with code.
Clarifying the purpose of an object. Sometimes if you can't find a good name
for something it's because it's trying to do too much or is otherwise
ill-conceived. Sometimes a good name will suggest other objects to create.
We will often suggest alternate names to each other during code review. It is
also common for a developer to try out a couple names in the developer
chatroom before settling on one.
This is the tale of one such occasion. Note that this is an incredibly trivial
example, but it's meant to demonstrate the discussion process we use to arrive
at a good name.
I was pairing with another developer on a design that let you attach arbitrary
traits to a record. We had a bit of code that checked to make sure that a value
was present, defined as not nil and not an empty string. 0 was a valid
value. Active Support's .blank? wouldn't work because it detects 0 as well
as '' and nil. In Rails this is normally less of an issue because you're
usually working with a string field or an integer field, but in our case we
had a string field that could be coerced to different types.
This would probably be good enough if we were using it in one place, but we
were using this logic in a couple places, so we thought we should encapsulate
it in a method. Also, even though this logic is certainly clear as to what it
does, it's slightly mysterious as to why it's doing it. Nothing terrible, but
it might cause a developer to slow down for a second and wonder, "What's so
special about nil and ''? Why didn't they just use .blank?" A second that
could be spared with a good, explanatory name.
So we asked around in the chatroom. Here were a couple suggestions of greater
and lesser absurdity:
.not_nil_or_empty_string?
.present_but_not_false_and_blank_but_not_empty?
.peanut_butter?
.nathans_choice?
.has_value?
I think it's safe to filter the list of candidates down to the first and last
options, .not_nil_or_empty_string? and .has_value?. The first one has the
virtue of describing exactly what's going on, but of course it's rather silly,
since the method name is almost the same as the expression it contains. The
second one is better but it reverses the question and clashes with a method on
Hash that takes an argument.
At this point one of the developers (the same one who suggested
.peanut_butter? actually) suggested .missing_value?. He pointed out that
this method name expressed the intention of the code. Specifically we were
asking, "Does the field not have a usable value? Is it missing a value?" This
name exposes an additional flaw in the silly name above: that name told the
developer too much about the implementation of the method. Another developer
should only have to know about the criteria used to determine validity if it
directly concerns the problem they're working on. For most cases it's enough to
know that the field validates against "missing" values.
As noted above, this is a trivial example. It may seem like it was a waste of
time to discuss this as a group, but in all it took about 10 minutes to work
through the options. Because finding good names is part of our discipline as a
group, our codebase as a whole is easier to understand and reason about than it
would be otherwise.